


Data engineering is a type of software engineering that focuses deeply on data — namely, data workflows, pipelines, and the ETL process (Extract, Transform, Load).
If you have heard about data science, then there is every probability that you might have heard about data engineering too.
Wait I thought they had similar role???
.... No dear, far from it.

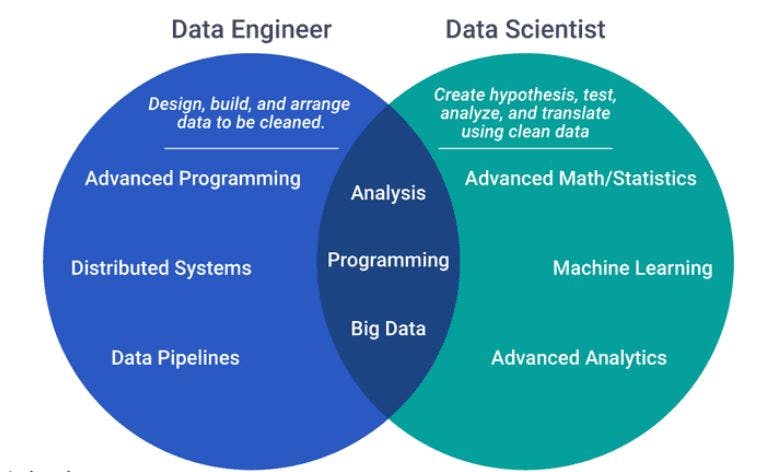
The difference between a data engineer and a data scientist is that data engineers focus on the infrastructure needed for data analysis, while data scientists perform data mining and data analysis functions.
Like data scientists, data engineers write code. They are highly analytical, and are interested in data visualization.
Unlike data scientists - and inspired by our more mature parent, software engineering - data engineers build tools, infrastructure, frameworks, and services. In fact, it's arguable that data engineering is much closer to software engineering than it is to a data scientist.
A data scientist's capability to convert data into value is largely correlated with the stage of her company's data infrastructure as well as how mature its warehouse is. So it is important that a data scientist should know enough about data engineering (same applies for data engineering) to carefully evaluate how her skills are aligned with the stage and need of the company.
Let's talk about Data engineering.
Imagine you have been hired as a data scientist in a startup and you want to use machine learning algorithms to implement certain model, but after much digging you realize your data is scattered amongst many databases, not only that, they are also not optimized for analyses and lots more of issue. This would be frustrating for you, but guess what, here comes Data engineers to the rescue.
It is the role of a data engineer to make your life as a data scientist easier. Data engineers are in charge of the delivery, storage, and processing of data. A data engineer’s job is to provide a reliable infrastructure for these functions. The data engineer gathers data from different sources, loads it into a single database that is ready to be used, at the same time they optimize the database scheme so it becomes faster to query, they also remove corrupt data.
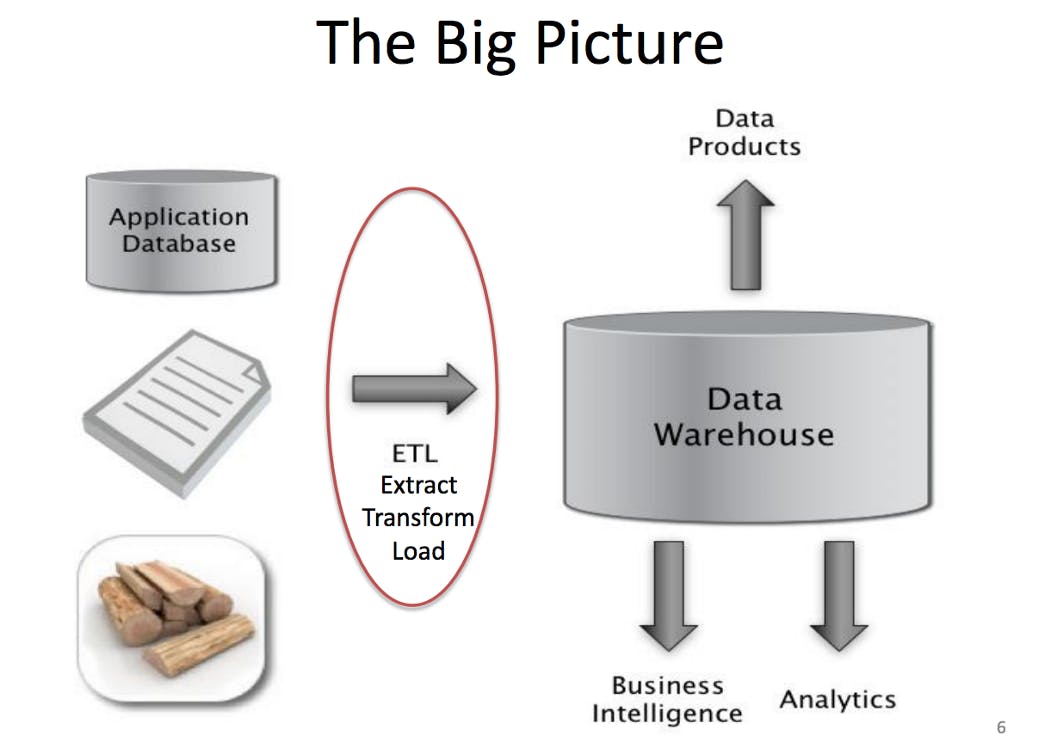 Put simply, data engineers help build data warehouses and form the crucial yet often overlooked backbone of any data science operation within an organization.
Put simply, data engineers help build data warehouses and form the crucial yet often overlooked backbone of any data science operation within an organization.
Wow, how important data engineers are in a data driven organization.
In relation to existing roles, the data engineering field could be thought of as a superset of business intelligence and data warehousing that brings more elements from software engineering. This discipline also integrates specialization around the operation of so called 'big data' distributed systems, along with concept around the extended Hadoop ecosystem, stream processing, and in computation at scale.
A data engineer develops, constructs, tests and maintains architectures such as databases and large-scale processing systems
Among the many valuable things that data engineers do, one of their highly sought-after skills is the ability to design, build, and maintain data warehouses. Without these foundational warehouses, every activities related to data science becomes either too expensive or not scalable. For example, without data infrastructure to support label collection or feature computation, building training data can be extremely time consuming.
Data engineers are responsible for expanding and optimizing data and data pipeline architecture and optimizing the data flow and collection for cross-functional teams. Typically the tasks of a data engineer are:
- Develop scalable data architecture
- Streamline data acquisition
- Set up processes to bring together data
- Clean corrupt data
Tools of the data engineer
First Data engineers are expert users of database systems such as MySQL and PostgreSQL. Their tasks begins and end with databases.
Data engineers use tools that can help them quickly process data which is essential to clean or aggregate data, or to join it together from different sources. Typically huge amount of data have to be processed. Instead of processing the data on one computer, data engineers use clusters of machines to process the data. Often these tools makes an abstraction of the underlying architecture and have a simple API. Some example of processing tools used by data engineer include spark, hive. Data engineers uses scheduling tools such as Apache airflow, oozie, to make sure data moves from one place to another within specific intervals.
How do you become a Data Engineer?
The general guidelines to acquire the skills you'll need to become a data engineer are as follows.
- Learn the right programming languages: Remember that a data engineer is first and foremost a software engineer, who also possesses skills in data analysis and statistics. Start by firming up your programming skills and learning programming language used by data engineers. SQL is the top language for creating and managing relational databases. Then move on to programming languages for statistical analysis and modelling, such as Python or R. Alongside these foundational skills, build your understanding of how these programming languages are applied in real world.
- Learn automation and scripting: Many of the tasks associated with transforming and analyzing data can be automated, especially if the task is repetitive and takes a long time. To automate tasks, you need to know scripting language syntax and operations, and product configurations such as workflow processes, escalations, and actions. Scripting languages can be used to automate certain tasks in a program or to extract information from a data set.
- Learn how databases work: Data engineers work with databases containing structured and unstructured data. Data engineers use SQL to transform and transport data from a data source (such as a relational database) to a data warehouse using ETL pipelines. They also tune databases for fast analysis and create table schemas.
- Learn how data processing works: Data processing is the conversion of raw data into an analyzable form. The most commonly used engine for parallel data processing - which is useful for large dataset - is Apache Spark. This data processing framework uses batch processing, which involves collecting data points that are grouped together within a specific time interval. Stream processing deals with continuous data collection in real-time. Each model has different used cases, batch processing is better when you don't need real-time data, whereas stream processing is essential for keeping business intelligence up to date.
- Learn cloud computing: The major advantage of cloud platforms is they centralize processing power and enable companies to store virtually unlimited amounts of data without the associated costs of on-premise storage solutions. The most popular cloud platforms are Amazon Web Services, Microsoft Azure, and Google Cloud Platform. Some job description require familiarity with a specific platform. Cloud platforms provide a range of services that are useful to data engineers, including the ability to use MPP databases that run across several machines and use parallel processing to do otherwise expensive data queries.
- Build a portfolio: Think of problems that can be solved by data science, and what data sources and pipelines will be needed to query the data. Predicting oil demand (and pricing), election outcomes, and the reproduction rates of animal populations are example of real-world problems that can be tackled using data science. Choose a discipline that matters to you such as the environment or government policy, and formulate a problem statement. Next, determine what datasets you'll need and find out if they're publicly accessible. Gather the data and build a pipeline that enables you to store and query that data.
Can one become a date engineer without a bachelor's or master's degree?
Well since there is no set university curriculum specifically for data engineering, it is still possible to become a data engineer without a degree.
- Becoming a data engineer starts with being a good software engineer, so if you choose not to obtain a degree, get certified as a software engineer through an online bootcamp or course, and gain work experience as a developer.
- Once you've proven yourself, start learning about distributed systems, data analysis and basic machine learning. You might find it useful to enroll in an online bootcamp focused on data science or engineering and reach you goal without having a degree.
Over the coming weeks I would be writing extensively about the career path, job description, and also practicing how to use some of these tools in data engineering. Watch out for this space and if you have any issue feel free to reach out to me on Twitter or send me a Mail.

O B R I G A D O